diff --git a/docs/zh_cn/tutorials/param_scheduler.md b/docs/zh_cn/tutorials/param_scheduler.md
index 31c0a655471559a6460d798f1ea03c79a69b10d0..ee41e3a74e42c33756c997a02b5cbf504cc7b664 100644
--- a/docs/zh_cn/tutorials/param_scheduler.md
+++ b/docs/zh_cn/tutorials/param_scheduler.md
@@ -1,39 +1,48 @@
# 优化器å‚数调整ç–略(Parameter Scheduler)
-在模型è®ç»ƒè¿‡ç¨‹ä¸ï¼Œæˆ‘们往往ä¸æ˜¯é‡‡ç”¨å›ºå®šçš„优化å‚数,例如å¦ä¹ 率ç‰ï¼Œä¼šéšç€è®ç»ƒè½®æ•°çš„å¢žåŠ è¿›è¡Œè°ƒæ•´ã€‚æœ€ç®€å•å¸¸è§çš„å¦ä¹ 率调整ç–略就是阶梯å¼ä¸‹é™ï¼Œä¾‹å¦‚æ¯éš”一段时间将å¦ä¹ 率é™ä½Žä¸ºåŽŸæ¥çš„å‡ åˆ†ä¹‹ä¸€ã€‚PyTorch ä¸æœ‰å¦ä¹ 率调度器 LRScheduler æ¥å¯¹å„ç§ä¸åŒçš„å¦ä¹ 率调整方å¼è¿›è¡ŒæŠ½è±¡ï¼Œä½†æ”¯æŒä»ç„¶æ¯”较有é™ï¼Œåœ¨ MMEngine ä¸ï¼Œæˆ‘们对其进行了拓展,实现了更通用的å‚数调度器,å¯ä»¥å¯¹å¦ä¹ 率ã€åŠ¨é‡ç‰ä¼˜åŒ–器相关的å‚数进行调整,并且支æŒå¤šä¸ªè°ƒåº¦å™¨è¿›è¡Œç»„åˆï¼Œåº”用更å¤æ‚的调度ç–略。
+在模型è®ç»ƒè¿‡ç¨‹ä¸ï¼Œæˆ‘们往往ä¸æ˜¯é‡‡ç”¨å›ºå®šçš„优化å‚数,例如å¦ä¹ 率ç‰ï¼Œä¼šéšç€è®ç»ƒè½®æ•°çš„å¢žåŠ è¿›è¡Œè°ƒæ•´ã€‚æœ€ç®€å•å¸¸è§çš„å¦ä¹ 率调整ç–略就是阶梯å¼ä¸‹é™ï¼Œä¾‹å¦‚æ¯éš”一段时间将å¦ä¹ 率é™ä½Žä¸ºåŽŸæ¥çš„å‡ åˆ†ä¹‹ä¸€ã€‚PyTorch ä¸æœ‰å¦ä¹ 率调度器 LRScheduler æ¥å¯¹å„ç§ä¸åŒçš„å¦ä¹ 率调整方å¼è¿›è¡ŒæŠ½è±¡ï¼Œä½†æ”¯æŒä»ç„¶æ¯”较有é™ï¼Œåœ¨ MMEngine ä¸ï¼Œæˆ‘们对其进行了拓展,实现了更通用的å‚数调度器 `mmengine.optim.scheduler`,å¯ä»¥å¯¹å¦ä¹ 率ã€åŠ¨é‡ç‰ä¼˜åŒ–器相关的å‚数进行调整,并且支æŒå¤šä¸ªè°ƒåº¦å™¨è¿›è¡Œç»„åˆï¼Œåº”用更å¤æ‚的调度ç–略。
## å‚数调度器的使用
-这里我们先简å•ä»‹ç»ä¸€ä¸‹å¦‚何使用 PyTorch 内置的å¦ä¹ 率调度器æ¥è¿›è¡Œå¦ä¹ 率的调整。下é¢æ˜¯ [PyTorch 官方文档](https://pytorch.org/docs/stable/optim.html) ä¸çš„一个例åï¼Œæˆ‘ä»¬æž„é€ ä¸€ä¸ª ExponentialLR,并且在æ¯ä¸ª epoch 结æŸåŽè°ƒç”¨ `scheduler.step()`ï¼Œå®žçŽ°äº†éš epoch 指数下é™çš„å¦ä¹ 率调整ç–略。
+这里我们先简å•ä»‹ç»ä¸€ä¸‹å¦‚何使用 PyTorch 内置的å¦ä¹ 率调度器æ¥è¿›è¡Œå¦ä¹ 率的调整。下é¢æ˜¯å‚考 [PyTorch 官方文档](https://pytorch.org/docs/stable/optim.html) 实现的一个例åï¼Œæˆ‘ä»¬æž„é€ ä¸€ä¸ª ExponentialLR,并且在æ¯ä¸ª epoch 结æŸåŽè°ƒç”¨ `scheduler.step()`ï¼Œå®žçŽ°äº†éš epoch 指数下é™çš„å¦ä¹ 率调整ç–略。
```python
-model = [Parameter(torch.randn(2, 2, requires_grad=True))]
+import torch
+from torch.optim import SGD
+from torch.optim.lr_scheduler import ExponentialLR
+
+model = torch.nn.Linear(1, 1)
+dataset = [torch.randn((1, 1, 1)) for _ in range(20)]
optimizer = SGD(model, 0.1)
scheduler = ExponentialLR(optimizer, gamma=0.9)
-for epoch in range(20):
- for input, target in dataset:
+for epoch in range(10):
+ for data in dataset:
optimizer.zero_grad()
- output = model(input)
- loss = loss_fn(output, target)
+ output = model(data)
+ loss = 1 - output
loss.backward()
optimizer.step()
scheduler.step()
```
-在 MMEngine ä¸ï¼Œæˆ‘们支æŒå¤§éƒ¨åˆ† PyTorch ä¸çš„å¦ä¹ 率调度器,例如 `ExponentialLR`,`LinearLR`,`StepLR`,`MultiStepLR` ç‰ï¼Œä½¿ç”¨æ–¹å¼ä¹ŸåŸºæœ¬ä¸€è‡´ï¼Œæ‰€æœ‰æ”¯æŒçš„调度器è§[调度器接å£æ–‡æ¡£](TODO)。åŒæ—¶å¢žåŠ 了对动é‡çš„调整,在类åä¸å°† `LR` 替æ¢æˆ `Momentum` å³å¯ï¼Œä¾‹å¦‚ `ExponentialMomentum`,`LinearMomentum`。更进一æ¥åœ°ï¼Œæˆ‘们实现了通用的å‚数调度器 ParamScheduler,用于调整优化器的ä¸çš„其他å‚数,包括 weight_decay ç‰ã€‚这个特性å¯ä»¥å¾ˆæ–¹ä¾¿åœ°é…置一些新算法ä¸å¤æ‚的调整ç–略。
+在 `mmengine.optim.scheduler` ä¸ï¼Œæˆ‘们支æŒå¤§éƒ¨åˆ† PyTorch ä¸çš„å¦ä¹ 率调度器,例如 `ExponentialLR`,`LinearLR`,`StepLR`,`MultiStepLR` ç‰ï¼Œä½¿ç”¨æ–¹å¼ä¹ŸåŸºæœ¬ä¸€è‡´ï¼Œæ‰€æœ‰æ”¯æŒçš„调度器è§[调度器接å£æ–‡æ¡£](TODO)。åŒæ—¶å¢žåŠ 了对动é‡çš„调整,在类åä¸å°† `LR` 替æ¢æˆ `Momentum` å³å¯ï¼Œä¾‹å¦‚ `ExponentialMomentum`,`LinearMomentum`。更进一æ¥åœ°ï¼Œæˆ‘们实现了通用的å‚数调度器 ParamScheduler,用于调整优化器的ä¸çš„其他å‚数,包括 weight_decay ç‰ã€‚这个特性å¯ä»¥å¾ˆæ–¹ä¾¿åœ°é…置一些新算法ä¸å¤æ‚的调整ç–略。
-å’Œ PyTorch 文档ä¸æ‰€ç»™ç¤ºä¾‹ä¸åŒï¼ŒMMEngine ä¸é€šå¸¸ä¸éœ€è¦æ‰‹åŠ¨æ¥å®žçŽ°è®ç»ƒå¾ªçŽ¯ä»¥åŠè°ƒç”¨ `optimizer.step()`,而是在执行器(Runner)ä¸å¯¹è®ç»ƒæµç¨‹è¿›è¡Œè‡ªåŠ¨ç®¡ç†ï¼ŒåŒæ—¶é€šè¿‡ Hook(例如 `SchedulerStepHook`)æ¥æŽ§åˆ¶å‚数调度器的执行。
+å’Œ PyTorch 文档ä¸æ‰€ç»™ç¤ºä¾‹ä¸åŒï¼ŒMMEngine ä¸é€šå¸¸ä¸éœ€è¦æ‰‹åŠ¨æ¥å®žçŽ°è®ç»ƒå¾ªçŽ¯ä»¥åŠè°ƒç”¨ `optimizer.step()`,而是在执行器(Runner)ä¸å¯¹è®ç»ƒæµç¨‹è¿›è¡Œè‡ªåŠ¨ç®¡ç†ï¼ŒåŒæ—¶é€šè¿‡ `ParamSchedulerHook` æ¥æŽ§åˆ¶å‚数调度器的执行。
### 使用å•ä¸€çš„å¦ä¹ 率调度器
如果整个è®ç»ƒè¿‡ç¨‹åªéœ€è¦ä½¿ç”¨ä¸€ä¸ªå¦ä¹ 率调度器, 那么和 PyTorch 自带的å¦ä¹ 率调度器没有差异。
```python
-optimizer = SGD(model, 0.1)
-scheduler = MultiStepLR(optimizer, by_epoch=True, milestones=[8, 11], gamma=0.1)
+from mmengine.optim.scheduler import MultiStepLR
+
+optimizer = SGD(model.parameters(), lr=0.01, momentum=0.9)
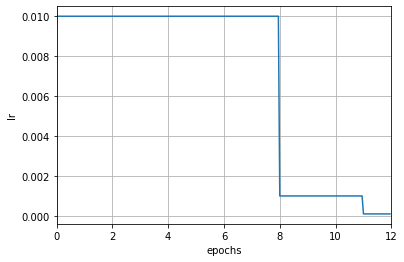
+scheduler = MultiStepLR(optimizer, milestones=[8, 11], gamma=0.1)
```
+
+
如果é…åˆæ³¨å†Œå™¨å’Œé…置文件使用的è¯ï¼Œæˆ‘们å¯ä»¥è®¾ç½®é…置文件ä¸çš„ `scheduler` å—段æ¥æŒ‡å®šä¼˜åŒ–器, 执行器(Runnerï¼‰ä¼šæ ¹æ®æ¤å—段以åŠæ‰§è¡Œå™¨ä¸çš„优化器自动构建å¦ä¹ 率调度器:
```python
@@ -41,12 +50,45 @@ scheduler = dict(type='MultiStepLR', by_epoch=True, milestones=[8, 11], gamma=0.
```
注æ„è¿™é‡Œå¢žåŠ äº†åˆå§‹åŒ–å‚æ•° `by_epoch`,控制的是å¦ä¹ 率调整频率,当其为 True 时表示按轮次(epoch) 调整,为 False 时表示按è¿ä»£æ¬¡æ•°ï¼ˆiteration)调整,默认值为 True。
-在上é¢çš„例åä¸ï¼Œè¡¨ç¤ºæŒ‰ç…§è½®æ¬¡è¿›è¡Œè°ƒæ•´ï¼Œæ¤æ—¶å…¶ä»–å‚æ•°çš„å•ä½å‡ä¸º epoch,例如 `milestones` ä¸çš„ \[8, 11\] 表示第 8 å’Œ 11 轮次结æŸæ—¶ï¼Œå¦ä¹ 率将会被调整为上一轮次的 0.1 å€ã€‚下é¢æ˜¯ä¸€ä¸ªæŒ‰ç…§è¿ä»£æ¬¡æ•°è¿›è¡Œè°ƒæ•´çš„例å,在第 60000 å’Œ 80000 次è¿ä»£ç»“æŸæ—¶ï¼Œå¦ä¹ 率将会被调整为原æ¥çš„ 0.1 å€ã€‚
+在上é¢çš„例åä¸ï¼Œè¡¨ç¤ºæŒ‰ç…§è½®æ¬¡è¿›è¡Œè°ƒæ•´ï¼Œæ¤æ—¶å…¶ä»–å‚æ•°çš„å•ä½å‡ä¸º epoch,例如 `milestones` ä¸çš„ \[8, 11\] 表示第 8 å’Œ 11 轮次结æŸæ—¶ï¼Œå¦ä¹ 率将会被调整为上一轮次的 0.1 å€ã€‚
+
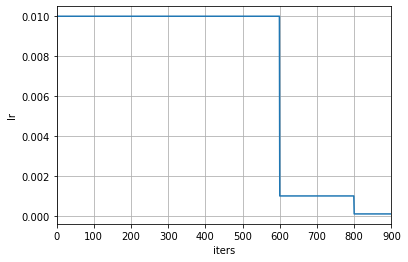
+当修改了å¦ä¹ 率调整频率åŽï¼Œè°ƒåº¦å™¨ä¸ä¸Žè®¡æ•°ç›¸å…³è®¾ç½®çš„å«ä¹‰ä¹Ÿä¼šç›¸åº”被改å˜ã€‚当 `by_epoch=True` 时,milestones ä¸çš„æ•°å—表示在哪些轮次进行å¦ä¹ 率衰å‡ï¼Œè€Œå½“ `by_epoch=False` æ—¶åˆ™è¡¨ç¤ºåœ¨è¿›è¡Œåˆ°ç¬¬å‡ æ¬¡è¿ä»£æ—¶è¿›è¡Œå¦ä¹ 率衰å‡ã€‚下é¢æ˜¯ä¸€ä¸ªæŒ‰ç…§è¿ä»£æ¬¡æ•°è¿›è¡Œè°ƒæ•´çš„例å,在第 600 å’Œ 800 次è¿ä»£ç»“æŸæ—¶ï¼Œå¦ä¹ 率将会被调整为原æ¥çš„ 0.1 å€ã€‚
+
+```python
+scheduler = dict(type='MultiStepLR', by_epoch=False, milestones=[600, 800], gamma=0.1)
+```
+
+
+
+若用户希望在é…置调度器时按轮次填写å‚æ•°çš„åŒæ—¶ä½¿ç”¨åŸºäºŽè¿ä»£çš„更新频率,MMEngine 的调度器也æ供了自动æ¢ç®—çš„æ–¹å¼ã€‚用户å¯ä»¥è°ƒç”¨ build_iter_from_epoch 方法,并æä¾›æ¯ä¸ªè®ç»ƒè½®æ¬¡çš„è¿ä»£æ¬¡æ•°ï¼Œå³å¯æž„é€ æŒ‰è¿ä»£æ¬¡æ•°æ›´æ–°çš„调度器对象:
+
+```python
+epoch_length = len(train_dataloader)
+scheduler = MultiStepLR.build_iter_from_epoch(optimizer, milestones=[8, 11], gamma=0.1, epoch_length=epoch_length)
+```
+
+如果使用é…置文件构建调度器,åªéœ€è¦åœ¨é…ç½®ä¸åŠ å…¥ `convert_to_iter_based=True`,执行器会自动调用 `build_iter_from_epoch` 将基于轮次的é…置文件转æ¢ä¸ºåŸºäºŽè¿ä»£æ¬¡æ•°çš„调度器对象:
```python
-scheduler = dict(type='MultiStepLR', by_epoch=False, milestones=[60000, 80000], gamma=0.1)
+scheduler = dict(type='MultiStepLR', by_epoch=True, milestones=[8, 11], gamma=0.1, convert_to_iter_based=True)
```
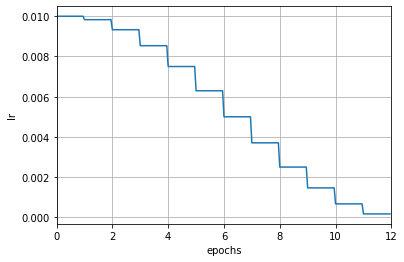
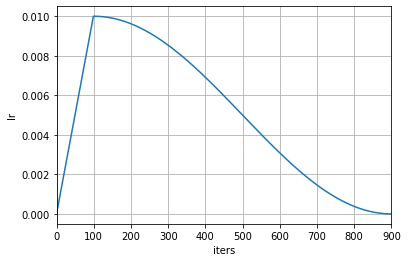
+为了能直观感å—这两ç§æ¨¡å¼çš„区别,我们ä¸è¿™é‡Œå†ä¸¾ä¸€ä¸ªä¾‹å。下é¢æ˜¯ä¸€ä¸ªæŒ‰è½®æ¬¡æ›´æ–°çš„余弦退ç«ï¼ˆCosineAnnealing)å¦ä¹ 率调度器,å¦ä¹ 率仅在æ¯ä¸ªè½®æ¬¡ç»“æŸåŽè¢«ä¿®æ”¹ï¼š
+
+```python
+scheduler = dict(type='CosineAnnealingLR', by_epoch=True, T_max=12)
+```
+
+
+
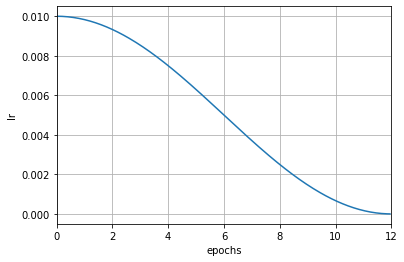
+而在使用自动æ¢ç®—åŽï¼Œå¦ä¹ 率会在æ¯æ¬¡è¿ä»£åŽè¢«ä¿®æ”¹ã€‚从下图å¯ä»¥çœ‹å‡ºï¼Œå¦ä¹ 率的å˜åŒ–更为平滑。
+
+```python
+scheduler = dict(type='CosineAnnealingLR', by_epoch=True, T_max=12, convert_to_iter_based=True)
+```
+
+
+
### 组åˆå¤šä¸ªå¦ä¹ 率调度器(以å¦ä¹ 率预çƒä¸ºä¾‹ï¼‰
有些算法在è®ç»ƒè¿‡ç¨‹ä¸ï¼Œå¹¶ä¸æ˜¯è‡ªå§‹è‡³ç»ˆæŒ‰ç…§æŸä¸ªè°ƒåº¦ç–略进行å¦ä¹ 率调整的。最常è§çš„例å是å¦ä¹ 率预çƒï¼Œæ¯”如在è®ç»ƒåˆšå¼€å§‹çš„若干è¿ä»£æ¬¡æ•°ä½¿ç”¨çº¿æ€§çš„调整ç–略将å¦ä¹ 率从一个较å°çš„值增长到æ£å¸¸ï¼Œç„¶åŽæŒ‰ç…§å¦å¤–的调整ç–略进行æ£å¸¸è®ç»ƒã€‚
@@ -60,7 +102,7 @@ scheduler = [
start_factor=0.001,
by_epoch=False, # 按è¿ä»£æ›´æ–°å¦ä¹ 率
begin=0,
- end=500), # 预çƒå‰ 500 次è¿ä»£
+ end=50), # 预çƒå‰ 50 次è¿ä»£
# 主å¦ä¹ 率调度器
dict(type='MultiStepLR',
by_epoch=True, # 按轮次更新å¦ä¹ 率
@@ -69,28 +111,32 @@ scheduler = [
]
```
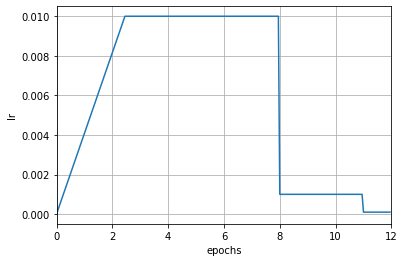
-注æ„è¿™é‡Œå¢žåŠ äº† `begin` å’Œ `end` å‚数,这两个å‚数指定了调度器的**生效区间**。生效区间通常åªåœ¨å¤šä¸ªè°ƒåº¦å™¨ç»„åˆæ—¶æ‰éœ€è¦åŽ»è®¾ç½®ï¼Œä½¿ç”¨å•ä¸ªè°ƒåº¦å™¨æ—¶å¯ä»¥å¿½ç•¥ã€‚当指定了 `begin` å’Œ `end` å‚数时,表示该调度器åªåœ¨ \[begin, end) 区间内生效,其å•ä½æ˜¯ç”± `by_epoch` å‚数决定。上述例åä¸é¢„çƒé˜¶æ®µ `LinearLR` çš„ `by_epoch` 为 False,表示该调度器åªåœ¨å‰ 500 次è¿ä»£ç”Ÿæ•ˆï¼Œè¶…过 500 次è¿ä»£åŽæ¤è°ƒåº¦å™¨ä¸å†ç”Ÿæ•ˆï¼Œç”±ç¬¬äºŒä¸ªè°ƒåº¦å™¨æ¥æŽ§åˆ¶å¦ä¹ çŽ‡ï¼Œå³ `MultiStepLR`。在组åˆä¸åŒè°ƒåº¦å™¨æ—¶ï¼Œå„调度器的 `by_epoch` å‚æ•°ä¸å¿…相åŒã€‚
+
+
+注æ„è¿™é‡Œå¢žåŠ äº† `begin` å’Œ `end` å‚数,这两个å‚数指定了调度器的**生效区间**。生效区间通常åªåœ¨å¤šä¸ªè°ƒåº¦å™¨ç»„åˆæ—¶æ‰éœ€è¦åŽ»è®¾ç½®ï¼Œä½¿ç”¨å•ä¸ªè°ƒåº¦å™¨æ—¶å¯ä»¥å¿½ç•¥ã€‚当指定了 `begin` å’Œ `end` å‚数时,表示该调度器åªåœ¨ \[begin, end) 区间内生效,其å•ä½æ˜¯ç”± `by_epoch` å‚数决定。上述例åä¸é¢„çƒé˜¶æ®µ `LinearLR` çš„ `by_epoch` 为 False,表示该调度器åªåœ¨å‰ 50 次è¿ä»£ç”Ÿæ•ˆï¼Œè¶…过 50 次è¿ä»£åŽæ¤è°ƒåº¦å™¨ä¸å†ç”Ÿæ•ˆï¼Œç”±ç¬¬äºŒä¸ªè°ƒåº¦å™¨æ¥æŽ§åˆ¶å¦ä¹ çŽ‡ï¼Œå³ `MultiStepLR`。在组åˆä¸åŒè°ƒåº¦å™¨æ—¶ï¼Œå„调度器的 `by_epoch` å‚æ•°ä¸å¿…相åŒã€‚
这里å†ä¸¾ä¸€ä¸ªä¾‹å:
```python
scheduler = [
- # 在 [0, 1000) è¿ä»£æ—¶ä½¿ç”¨çº¿æ€§å¦ä¹ 率
+ # 在 [0, 100) è¿ä»£æ—¶ä½¿ç”¨çº¿æ€§å¦ä¹ 率
dict(type='LinearLR',
start_factor=0.001,
by_epoch=False,
begin=0,
- end=1000),
- # 在 [1000, 9000) è¿ä»£æ—¶ä½¿ç”¨ä½™å¼¦å¦ä¹ 率
+ end=100),
+ # 在 [100, 900) è¿ä»£æ—¶ä½¿ç”¨ä½™å¼¦å¦ä¹ 率
dict(type='CosineAnnealingLR',
- T_max=8000,
+ T_max=800,
by_epoch=False,
- begin=1000,
- end=9000)
+ begin=100,
+ end=900)
]
```
-上述例å表示在è®ç»ƒçš„å‰ 1000 次è¿ä»£æ—¶ä½¿ç”¨çº¿æ€§çš„å¦ä¹ 率预çƒï¼Œç„¶åŽåœ¨ç¬¬ 1000 到第 9000 次è¿ä»£æ—¶ä½¿ç”¨å‘¨æœŸä¸º 8000 的余弦退ç«å¦ä¹ 率调度器使å¦ä¹ 率按照余弦函数é€æ¸ä¸‹é™ä¸º 0 。
+
+
+上述例å表示在è®ç»ƒçš„å‰ 100 次è¿ä»£æ—¶ä½¿ç”¨çº¿æ€§çš„å¦ä¹ 率预çƒï¼Œç„¶åŽåœ¨ç¬¬ 100 到第 900 次è¿ä»£æ—¶ä½¿ç”¨å‘¨æœŸä¸º 800 的余弦退ç«å¦ä¹ 率调度器使å¦ä¹ 率按照余弦函数é€æ¸ä¸‹é™ä¸º 0 。
我们å¯ä»¥ç»„åˆä»»æ„多个调度器,既å¯ä»¥ä½¿ç”¨ MMEngine ä¸å·²ç»æ”¯æŒçš„调度器,也å¯ä»¥å®žçŽ°è‡ªå®šä¹‰çš„调度器。
如果相邻两个调度器的生效区间没有紧邻,而是有一段区间没有被覆盖,那么这段区间的å¦ä¹ 率维æŒä¸å˜ã€‚而如果两个调度器的生效区间å‘生了é‡å ,则对多组调度器å åŠ ä½¿ç”¨ï¼Œå¦ä¹ 率的调整会按照调度器é…置文件ä¸çš„顺åºè§¦å‘(行为与 PyTorch ä¸ [`ChainedScheduler`](https://pytorch.org/docs/stable/generated/torch.optim.lr_scheduler.ChainedScheduler.html#chainedscheduler) 一致)。