From 5e1ef1dd6cfd7b8ecbf051b052504b8c35a05b04 Mon Sep 17 00:00:00 2001
From: RangiLyu <lyuchqi@gmail.com>
Date: Mon, 22 Aug 2022 11:30:49 +0800
Subject: [PATCH] [Docs] Update runner documents. (#430)
* [Doc] Update runner documents.
* update
* fix link
* update
* update
* Update import manner of Runner
Co-authored-by: Wenwei Zhang <40779233+ZwwWayne@users.noreply.github.com>
---
docs/zh_cn/design/runner.md | 160 ++++++++++++++++
docs/zh_cn/tutorials/runner.md | 332 ++++++++++++++-------------------
2 files changed, 304 insertions(+), 188 deletions(-)
create mode 100644 docs/zh_cn/design/runner.md
diff --git a/docs/zh_cn/design/runner.md b/docs/zh_cn/design/runner.md
new file mode 100644
index 00000000..80aeb0e5
--- /dev/null
+++ b/docs/zh_cn/design/runner.md
@@ -0,0 +1,160 @@
+# 执行器的设计
+
+深度å¦ä¹ 算法的è®ç»ƒã€éªŒè¯å’Œæµ‹è¯•é€šå¸¸éƒ½æ‹¥æœ‰ç›¸ä¼¼çš„æµç¨‹ï¼Œå› æ¤ï¼Œ MMEngine 抽象出了执行器æ¥è´Ÿè´£é€šç”¨çš„算法模型的è®ç»ƒã€æµ‹è¯•ã€æŽ¨ç†ä»»åŠ¡ã€‚用户一般å¯ä»¥ç›´æŽ¥ä½¿ç”¨ MMEngine ä¸çš„默认执行器,也å¯ä»¥å¯¹æ‰§è¡Œå™¨è¿›è¡Œä¿®æ”¹ä»¥æ»¡è¶³å®šåˆ¶åŒ–需求。
+
+在介ç»æ‰§è¡Œå™¨çš„设计之å‰ï¼Œæˆ‘ä»¬å…ˆä¸¾å‡ ä¸ªä¾‹åæ¥å¸®åŠ©ç”¨æˆ·ç†è§£ä¸ºä»€ä¹ˆéœ€è¦æ‰§è¡Œå™¨ã€‚下é¢æ˜¯ä¸€æ®µä½¿ç”¨ PyTorch 进行模型è®ç»ƒçš„伪代ç :
+
+```python
+model = ResNet()
+optimizer = SGD(model.parameters(), lr=0.01, momentum=0.9)
+train_dataset = ImageNetDataset(...)
+train_dataloader = DataLoader(train_dataset, ...)
+
+for i in range(max_epochs):
+ for data_batch in train_dataloader:
+ optimizer.zero_grad()
+ outputs = model(data_batch)
+ loss = loss_func(outputs, data_batch)
+ loss.backward()
+ optimizer.step()
+```
+
+下é¢æ˜¯ä¸€æ®µä½¿ç”¨ PyTorch 进行模型测试的伪代ç :
+
+```python
+model = ResNet()
+model.load_state_dict(torch.load(CKPT_PATH))
+model.eval()
+
+test_dataset = ImageNetDataset(...)
+test_dataloader = DataLoader(test_dataset, ...)
+
+for data_batch in test_dataloader:
+ outputs = model(data_batch)
+ acc = calculate_acc(outputs, data_batch)
+```
+
+下é¢æ˜¯ä¸€æ®µä½¿ç”¨ PyTorch 进行模型推ç†çš„伪代ç :
+
+```python
+model = ResNet()
+model.load_state_dict(torch.load(CKPT_PATH))
+model.eval()
+
+for img in imgs:
+ prediction = model(img)
+```
+
+å¯ä»¥ä»Žä¸Šé¢çš„三段代ç 看出,这三个任务的执行æµç¨‹éƒ½å¯ä»¥å½’纳为构建模型ã€è¯»å–æ•°æ®ã€å¾ªçŽ¯è¿ä»£ç‰æ¥éª¤ã€‚上述代ç 都是以图åƒåˆ†ç±»ä¸ºä¾‹ï¼Œä½†ä¸è®ºæ˜¯å›¾åƒåˆ†ç±»è¿˜æ˜¯ç›®æ ‡æ£€æµ‹æˆ–是图åƒåˆ†å‰²ï¼Œéƒ½è„±ç¦»ä¸äº†è¿™å¥—范å¼ã€‚
+å› æ¤ï¼Œæˆ‘们将模型的è®ç»ƒã€éªŒè¯ã€æµ‹è¯•çš„æµç¨‹æ•´åˆèµ·æ¥ï¼Œå½¢æˆäº†æ‰§è¡Œå™¨ã€‚在执行器ä¸ï¼Œæˆ‘们åªéœ€è¦å‡†å¤‡å¥½æ¨¡åž‹ã€æ•°æ®ç‰ä»»åŠ¡å¿…须的模å—或是这些模å—çš„é…置文件,执行器会自动完æˆä»»åŠ¡æµç¨‹çš„准备和执行。
+é€šè¿‡ä½¿ç”¨æ‰§è¡Œå™¨ä»¥åŠ MMEngine ä¸ä¸°å¯Œçš„功能模å—,用户ä¸å†éœ€è¦æ‰‹åŠ¨æ建è®ç»ƒæµ‹è¯•çš„æµç¨‹ï¼Œä¹Ÿä¸å†éœ€è¦åŽ»å¤„ç†åˆ†å¸ƒå¼ä¸Žéžåˆ†å¸ƒå¼è®ç»ƒçš„区别,å¯ä»¥ä¸“注于算法和模型本身。
+
+
+
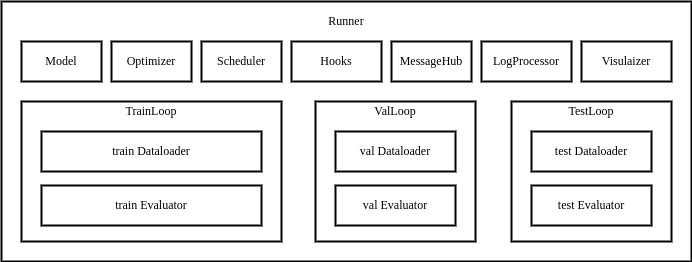
+MMEngine 的执行器内包å«è®ç»ƒã€æµ‹è¯•ã€éªŒè¯æ‰€éœ€çš„å„个模å—,以åŠå¾ªçŽ¯æŽ§åˆ¶å™¨ï¼ˆLoop)和[é’©å(Hook)](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/hook.html)。用户通过æä¾›é…置文件或已构建完æˆçš„模å—,执行器将自动完æˆè¿è¡ŒçŽ¯å¢ƒçš„é…置,模å—的构建和组åˆï¼Œæœ€ç»ˆé€šè¿‡å¾ªçŽ¯æŽ§åˆ¶å™¨æ‰§è¡Œä»»åŠ¡å¾ªçŽ¯ã€‚执行器对外æ供三个接å£ï¼š`train`, `val`, `test`,当调用这三个接å£æ—¶ï¼Œä¾¿ä¼šè¿è¡Œå¯¹åº”的循环控制器,并在循环的è¿è¡Œè¿‡ç¨‹ä¸è°ƒç”¨é’©å模å—å„个ä½ç‚¹çš„é’©å函数。
+
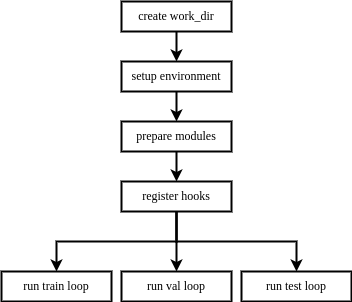
+当用户构建一个执行器并调用è®ç»ƒã€éªŒè¯ã€æµ‹è¯•çš„接å£æ—¶ï¼Œæ‰§è¡Œå™¨çš„执行æµç¨‹å¦‚下:
+创建工作目录 -> é…ç½®è¿è¡ŒçŽ¯å¢ƒ -> å‡†å¤‡ä»»åŠ¡æ‰€éœ€æ¨¡å— -> 注册钩å -> è¿è¡Œå¾ªçŽ¯
+
+
+
+执行器具有延迟åˆå§‹åŒ–(Lazy Initialization)的特性,在åˆå§‹åŒ–执行器时,并ä¸éœ€è¦ä¾èµ–è®ç»ƒã€éªŒè¯å’Œæµ‹è¯•çš„å…¨é‡æ¨¡å—,åªæœ‰å½“è¿è¡ŒæŸä¸ªå¾ªçŽ¯æŽ§åˆ¶å™¨æ—¶ï¼Œæ‰ä¼šæ£€æŸ¥æ‰€éœ€æ¨¡å—是å¦æž„å»ºã€‚å› æ¤ï¼Œè‹¥ç”¨æˆ·åªéœ€è¦æ‰§è¡Œè®ç»ƒã€éªŒè¯æˆ–测试ä¸çš„æŸä¸€é¡¹åŠŸèƒ½ï¼Œåªéœ€æ供对应的模å—或模å—çš„é…ç½®å³å¯ã€‚
+
+## 循环控制器
+
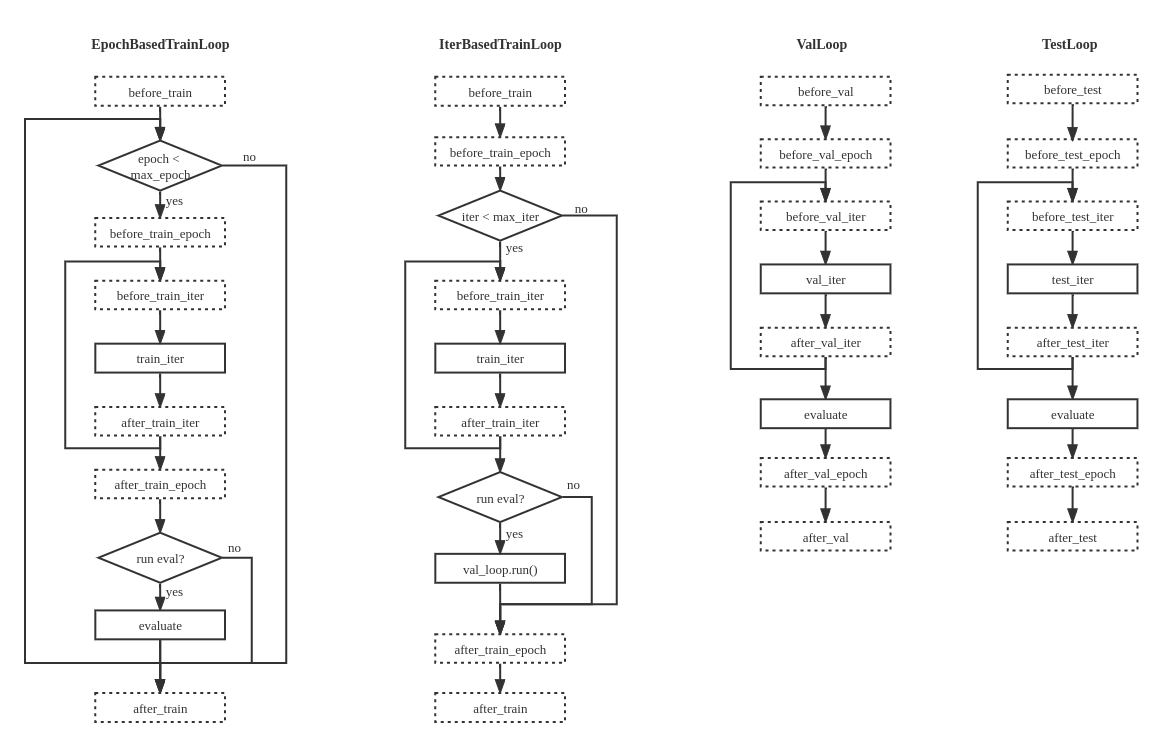
+在 MMEngine ä¸ï¼Œæˆ‘们将任务的执行æµç¨‹æŠ½è±¡æˆå¾ªçŽ¯æŽ§åˆ¶å™¨ï¼ˆLoopï¼‰ï¼Œå› ä¸ºå¤§éƒ¨åˆ†çš„æ·±åº¦å¦ä¹ 任务执行æµç¨‹éƒ½å¯ä»¥å½’纳为模型在一组或多组数æ®ä¸Šè¿›è¡Œå¾ªçŽ¯è¿ä»£ã€‚
+MMEngine 内æ供了四ç§é»˜è®¤çš„循环控制器:
+
+- EpochBasedTrainLoop 基于轮次的è®ç»ƒå¾ªçŽ¯
+- IterBasedTrainLoop 基于è¿ä»£æ¬¡æ•°çš„è®ç»ƒå¾ªçŽ¯
+- ValLoop æ ‡å‡†çš„éªŒè¯å¾ªçŽ¯
+- TestLoop æ ‡å‡†çš„æµ‹è¯•å¾ªçŽ¯
+
+
+
+MMEngine ä¸çš„默认执行器和循环控制器能够完æˆå¤§éƒ¨åˆ†çš„深度å¦ä¹ 任务,但ä¸å¯é¿å…会å˜åœ¨æ— æ³•æ»¡è¶³çš„æƒ…å†µã€‚æœ‰çš„ç”¨æˆ·å¸Œæœ›èƒ½å¤Ÿå¯¹æ‰§è¡Œå™¨è¿›è¡Œæ›´å¤šè‡ªå®šä¹‰ä¿®æ”¹ï¼Œå› æ¤ï¼ŒMMEngine 支æŒè‡ªå®šä¹‰æ¨¡åž‹çš„è®ç»ƒã€éªŒè¯ä»¥åŠæµ‹è¯•çš„æµç¨‹ã€‚
+
+用户å¯ä»¥é€šè¿‡ç»§æ‰¿å¾ªçŽ¯åŸºç±»æ¥å®žçŽ°è‡ªå·±çš„è®ç»ƒæµç¨‹ã€‚循环基类需è¦æ供两个输入:`runner` 执行器的实例和 `loader` 循环所需è¦è¿ä»£çš„è¿ä»£å™¨ã€‚
+用户如果有自定义的需求,也å¯ä»¥å¢žåŠ 更多的输入å‚数。MMEngine ä¸åŒæ ·æ供了 LOOPS 注册器对循环类进行管ç†ï¼Œç”¨æˆ·å¯ä»¥å‘注册器内注册自定义的循环模å—,
+然åŽåœ¨é…置文件的 `train_cfg`ã€`val_cfg`ã€`test_cfg` ä¸å¢žåŠ `type` å—段æ¥æŒ‡å®šä½¿ç”¨ä½•ç§å¾ªçŽ¯ã€‚
+用户å¯ä»¥åœ¨è‡ªå®šä¹‰çš„循环ä¸å®žçŽ°ä»»æ„的执行逻辑,也å¯ä»¥å¢žåŠ æˆ–åˆ å‡é’©å(hook)点ä½ï¼Œä½†éœ€è¦æ³¨æ„的是一旦钩å点ä½è¢«ä¿®æ”¹ï¼Œé»˜è®¤çš„é’©å函数å¯èƒ½ä¸ä¼šè¢«æ‰§è¡Œï¼Œå¯¼è‡´ä¸€äº›è®ç»ƒè¿‡ç¨‹ä¸é»˜è®¤å‘生的行为å‘生å˜åŒ–。
+å› æ¤ï¼Œæˆ‘们强烈建议用户按照本文档ä¸å®šä¹‰çš„循环执行æµç¨‹å›¾ä»¥åŠ[é’©å设计](https://mmengine.readthedocs.io/zh_CN/latest/design/hook.html) 去é‡è½½å¾ªçŽ¯åŸºç±»ã€‚
+
+```python
+from mmengine.registry import LOOPS, HOOKS
+from mmengine.runner import BaseLoop
+from mmengine.hooks import Hook
+
+
+# 自定义验è¯å¾ªçŽ¯
+@LOOPS.register_module()
+class CustomValLoop(BaseLoop):
+ def __init__(self, runner, dataloader, evaluator, dataloader2):
+ super().__init__(runner, dataloader, evaluator)
+ self.dataloader2 = runner.build_dataloader(dataloader2)
+
+ def run(self):
+ self.runner.call_hooks('before_val_epoch')
+ for idx, data_batch in enumerate(self.dataloader):
+ self.runner.call_hooks(
+ 'before_val_iter', batch_idx=idx, data_batch=data_batch)
+ outputs = self.run_iter(idx, data_batch)
+ self.runner.call_hooks(
+ 'after_val_iter', batch_idx=idx, data_batch=data_batch, outputs=outputs)
+ metric = self.evaluator.evaluate()
+
+ # å¢žåŠ é¢å¤–的验è¯å¾ªçŽ¯
+ for idx, data_batch in enumerate(self.dataloader2):
+ # å¢žåŠ é¢å¤–çš„é’©å点ä½
+ self.runner.call_hooks(
+ 'before_valloader2_iter', batch_idx=idx, data_batch=data_batch)
+ self.run_iter(idx, data_batch)
+ # å¢žåŠ é¢å¤–çš„é’©å点ä½
+ self.runner.call_hooks(
+ 'after_valloader2_iter', batch_idx=idx, data_batch=data_batch, outputs=outputs)
+ metric2 = self.evaluator.evaluate()
+
+ ...
+
+ self.runner.call_hooks('after_val_epoch')
+
+
+# 定义é¢å¤–点ä½çš„é’©åç±»
+@HOOKS.register_module()
+class CustomValHook(Hook):
+ def before_valloader2_iter(self, batch_idx, data_batch):
+ ...
+
+ def after_valloader2_iter(self, batch_idx, data_batch, outputs):
+ ...
+
+```
+
+上é¢çš„例åä¸å®žçŽ°äº†ä¸€ä¸ªä¸Žé»˜è®¤éªŒè¯å¾ªçŽ¯ä¸ä¸€æ ·çš„自定义验è¯å¾ªçŽ¯ï¼Œå®ƒåœ¨ä¸¤ä¸ªä¸åŒçš„验è¯é›†ä¸Šè¿›è¡ŒéªŒè¯ï¼ŒåŒæ—¶å¯¹ç¬¬äºŒæ¬¡éªŒè¯å¢žåŠ 了é¢å¤–çš„é’©å点ä½ï¼Œå¹¶åœ¨æœ€åŽå¯¹ä¸¤ä¸ªéªŒè¯ç»“果进行进一æ¥çš„处ç†ã€‚在实现了自定义的循环类之åŽï¼Œ
+åªéœ€è¦åœ¨é…置文件的 `val_cfg` 内设置 `type='CustomValLoop'`ï¼Œå¹¶æ·»åŠ é¢å¤–çš„é…ç½®å³å¯ã€‚
+
+```python
+# 自定义验è¯å¾ªçŽ¯
+val_cfg = dict(type='CustomValLoop', dataloader2=dict(dataset=dict(type='ValDataset2'), ...))
+# é¢å¤–点ä½çš„é’©å
+custom_hooks = [dict(type='CustomValHook')]
+```
+
+## 自定义执行器
+
+更进一æ¥ï¼Œå¦‚果默认执行器ä¸ä¾ç„¶æœ‰å…¶ä»–æ— æ³•æ»¡è¶³éœ€æ±‚çš„éƒ¨åˆ†ï¼Œç”¨æˆ·å¯ä»¥åƒè‡ªå®šä¹‰å…¶ä»–模å—ä¸€æ ·ï¼Œé€šè¿‡ç»§æ‰¿é‡å†™çš„æ–¹å¼ï¼Œå®žçŽ°è‡ªå®šä¹‰çš„执行器。执行器åŒæ ·ä¹Ÿå¯ä»¥é€šè¿‡æ³¨å†Œå™¨è¿›è¡Œç®¡ç†ã€‚具体实现æµç¨‹ä¸Žå…¶ä»–模å—æ— å¼‚ï¼šç»§æ‰¿ MMEngine ä¸çš„ Runner,é‡å†™éœ€è¦ä¿®æ”¹çš„å‡½æ•°ï¼Œæ·»åŠ è¿› RUNNERS 注册器ä¸ï¼Œæœ€åŽåœ¨é…置文件ä¸æŒ‡å®š `runner_type` å³å¯ã€‚
+
+```python
+from mmengine.registry import RUNNERS
+from mmengine.runner import Runner
+
+@RUNNERS.register_module()
+class CustomRunner(Runner):
+
+ def setup_env(self):
+ ...
+```
+
+上述例å实现了一个自定义的执行器,并é‡å†™äº† `setup_env` 函数,然åŽæ·»åŠ 进了 RUNNERS 注册器ä¸ï¼Œå®Œæˆäº†è¿™äº›æ¥éª¤ä¹‹åŽï¼Œä¾¿å¯ä»¥åœ¨é…置文件ä¸è®¾ç½® `runner_type='CustomRunner'` æ¥æž„建自定义的执行器。
+
+ä½ å¯èƒ½è¿˜æƒ³é˜…读[执行器的教程](../tutorials/runner.md)或者[执行器的 API 文档](https://mmengine.readthedocs.io/zh_CN/latest/api/runner.html)。
diff --git a/docs/zh_cn/tutorials/runner.md b/docs/zh_cn/tutorials/runner.md
index 1e3237b9..6aa098a9 100644
--- a/docs/zh_cn/tutorials/runner.md
+++ b/docs/zh_cn/tutorials/runner.md
@@ -1,119 +1,160 @@
# 执行器(Runner)
-OpenMMLab 的算法库ä¸æ供了å„ç§ç®—法模型的è®ç»ƒã€æµ‹è¯•ã€æŽ¨ç†åŠŸèƒ½ï¼Œè¿™äº›åŠŸèƒ½åœ¨ä¸åŒç®—法方å‘上都有ç€ç›¸ä¼¼çš„接å£ã€‚
-å› æ¤ï¼Œ MMEngine 抽象出了执行器æ¥è´Ÿè´£é€šç”¨çš„算法模型的è®ç»ƒã€æµ‹è¯•ã€æŽ¨ç†ä»»åŠ¡ã€‚
-用户一般å¯ä»¥ç›´æŽ¥ä½¿ç”¨ MMEngine ä¸çš„默认执行器,也å¯ä»¥å¯¹æ‰§è¡Œå™¨è¿›è¡Œä¿®æ”¹ä»¥æ»¡è¶³å®šåˆ¶åŒ–需求。
+深度å¦ä¹ 算法的è®ç»ƒã€éªŒè¯å’Œæµ‹è¯•é€šå¸¸éƒ½æ‹¥æœ‰ç›¸ä¼¼çš„æµç¨‹ï¼Œå› æ¤ MMEngine æ供了执行器以帮助用户简化这些任务的实现æµç¨‹ã€‚ 用户åªéœ€è¦å‡†å¤‡å¥½æ¨¡åž‹è®ç»ƒã€éªŒè¯ã€æµ‹è¯•æ‰€éœ€è¦çš„模å—构建执行器,便能够通过简å•è°ƒç”¨æ‰§è¡Œå™¨çš„接å£æ¥å®Œæˆè¿™äº›ä»»åŠ¡ã€‚用户如果需è¦ä½¿ç”¨è¿™å‡ 项功能ä¸çš„æŸä¸€é¡¹ï¼Œåªéœ€è¦å‡†å¤‡å¥½å¯¹åº”功能所ä¾èµ–的模å—å³å¯ã€‚
-在介ç»å¦‚何使用执行器之å‰ï¼Œæˆ‘ä»¬å…ˆä¸¾å‡ ä¸ªä¾‹åæ¥å¸®åŠ©ç”¨æˆ·ç†è§£ä¸ºä»€ä¹ˆéœ€è¦æ‰§è¡Œå™¨ã€‚
+用户å¯ä»¥æ‰‹åŠ¨æž„建这些模å—的实例,也å¯ä»¥é€šè¿‡ç¼–写[é…置文件](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/config.html),
+由执行器自动从[注册器](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/registry.html)ä¸æž„建所需è¦çš„模å—,我们推è使用åŽä¸€ç§æ–¹å¼ã€‚
-下é¢æ˜¯ä¸€æ®µä½¿ç”¨ PyTorch 进行模型è®ç»ƒçš„伪代ç :
+## 手动构建模å—æ¥ä½¿ç”¨æ‰§è¡Œå™¨
-```python
-model = ResNet()
-optimizer = SGD(model.parameters(), lr=0.01, momentum=0.9)
-train_dataset = ImageNetDataset(...)
-train_dataloader = DataLoader(train_dataset, ...)
-
-for i in range(max_epochs):
- for data_batch in train_dataloader:
- optimizer.zero_grad()
- outputs = model(data_batch)
- loss = loss_func(outputs, data_batch)
- loss.backward()
- optimizer.step()
-```
+### 手动构建模å—进行è®ç»ƒ
-下é¢æ˜¯ä¸€æ®µä½¿ç”¨ PyTorch 进行模型测试的伪代ç :
+如上文所说,使用执行器的æŸä¸€é¡¹åŠŸèƒ½æ—¶éœ€è¦å‡†å¤‡å¥½å¯¹åº”功能所ä¾èµ–的模å—。以使用执行器的è®ç»ƒåŠŸèƒ½ä¸ºä¾‹ï¼Œç”¨æˆ·éœ€è¦å‡†å¤‡[模型](TODO) ã€[优化器](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/optimizer.html) ã€
+[å‚数调度器](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/param_scheduler.html) 还有è®ç»ƒ[æ•°æ®é›†](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/basedataset.html) 。
```python
-model = ResNet()
-model.load_state_dict(torch.load(CKPT_PATH))
-model.eval()
-
-test_dataset = ImageNetDataset(...)
-test_dataloader = DataLoader(test_dataset, ...)
-
-for data_batch in test_dataloader:
- outputs = model(data_batch)
- acc = calculate_acc(outputs, data_batch)
+# 准备è®ç»ƒä»»åŠ¡æ‰€éœ€è¦çš„模å—
+import torch
+from torch import nn
+from torchvision import transforms
+from torchvision import datasets
+from torch.utils.data import DataLoader
+from mmengine.model import BaseModel
+from mmengine.optim.scheduler import MultiStepLR
+
+# 定义一个多层感知机网络
+class Network(BaseModel):
+ def __init__(self):
+ super().__init__()
+ self.mlp = nn.Sequential(nn.Linear(28 * 28, 128), nn.ReLU(), nn.Linear(128, 128), nn.ReLU(), nn.Linear(128, 10))
+ self.loss = nn.CrossEntropyLoss()
+
+ def forward(self, batch_inputs: torch.Tensor, data_samples = None, mode: str = 'tensor'):
+ x = batch_inputs.flatten(1)
+ x = self.mlp(x)
+ if mode == 'loss':
+ return {'loss': self.loss(x, data_samples)}
+ elif mode == 'predict':
+ return x.argmax(1)
+ else:
+ return x
+
+model = Network()
+
+# 构建优化器
+optimzier = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
+# 构建å‚数调度器用于调整å¦ä¹ 率
+lr_scheduler = MultiStepLR(milestones=[2], by_epoch=True)
+# 构建手写数å—识别 (MNIST) æ•°æ®é›†
+train_dataset = datasets.MNIST(root="MNIST", download=True, train=True, transform=transforms.ToTensor())
+# 构建数æ®åŠ 载器
+train_dataloader = DataLoader(dataset=train_dataset, batch_size=10, num_workers=2)
```
-下é¢æ˜¯ä¸€æ®µä½¿ç”¨ PyTorch 进行模型推ç†çš„伪代ç :
+在创建完符åˆä¸Šè¿°æ–‡æ¡£è§„范的模å—的对象åŽï¼Œå°±å¯ä»¥ä½¿ç”¨è¿™äº›æ¨¡å—åˆå§‹åŒ–执行器:
```python
-model = ResNet()
-model.load_state_dict(torch.load(CKPT_PATH))
-model.eval()
-
-for img in imgs:
- prediction = model(img)
-```
+from mmengine.runner import Runner
-å¯ä»¥ä»Žä¸Šé¢çš„三段代ç 看出,这三个任务的执行æµç¨‹éƒ½å¯ä»¥å½’纳为构建模型ã€è¯»å–æ•°æ®ã€å¾ªçŽ¯è¿ä»£ç‰æ¥éª¤ã€‚上述代ç 都是以图åƒåˆ†ç±»ä¸ºä¾‹ï¼Œä½†ä¸è®ºæ˜¯å›¾åƒåˆ†ç±»è¿˜æ˜¯ç›®æ ‡æ£€æµ‹æˆ–是图åƒåˆ†å‰²ï¼Œéƒ½è„±ç¦»ä¸äº†è¿™å¥—范å¼ã€‚
-å› æ¤ï¼Œæˆ‘们将模型的è®ç»ƒã€éªŒè¯ã€æµ‹è¯•çš„æµç¨‹æ•´åˆèµ·æ¥ï¼Œå½¢æˆäº†æ‰§è¡Œå™¨ã€‚在执行器ä¸ï¼Œæˆ‘们åªéœ€è¦å‡†å¤‡å¥½æ¨¡åž‹ã€æ•°æ®ç‰ä»»åŠ¡å¿…须的模å—或是这些模å—çš„é…置文件,执行器会自动完æˆä»»åŠ¡æµç¨‹çš„准备和执行。
-é€šè¿‡ä½¿ç”¨æ‰§è¡Œå™¨ä»¥åŠ MMEngine ä¸ä¸°å¯Œçš„功能模å—,用户ä¸å†éœ€è¦æ‰‹åŠ¨æ建è®ç»ƒæµ‹è¯•çš„æµç¨‹ï¼Œä¹Ÿä¸å†éœ€è¦åŽ»å¤„ç†åˆ†å¸ƒå¼ä¸Žéžåˆ†å¸ƒå¼è®ç»ƒçš„区别,å¯ä»¥ä¸“注于算法和模型本身。
-## 如何使用执行器
+# è®ç»ƒç›¸å…³å‚数设置,按轮次è®ç»ƒï¼Œè®ç»ƒ3è½®
+train_cfg = dict(by_epoch=True, max_epoch=3)
-MMEngine ä¸é»˜è®¤çš„执行器支æŒæ‰§è¡Œæ¨¡åž‹çš„è®ç»ƒã€æµ‹è¯•ä»¥åŠæŽ¨ç†ã€‚用户如果需è¦ä½¿ç”¨è¿™å‡ 项功能ä¸çš„æŸä¸€é¡¹ï¼Œå°±éœ€è¦å‡†å¤‡å¥½å¯¹åº”功能所ä¾èµ–的模å—。
-用户å¯ä»¥æ‰‹åŠ¨æž„建这些模å—的实例,也å¯ä»¥é€šè¿‡ç¼–写[é…置文件](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/config.html) ,
-由执行器自动从[注册器](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/registry.html) ä¸æž„建所需è¦çš„模å—。这两ç§ä½¿ç”¨æ–¹å¼ä¸ï¼Œæˆ‘们更推èåŽè€…。
+# åˆå§‹åŒ–执行器
+runner = Runner(model,
+ work_dir='./train_mnist', # 工作目录,用于ä¿å˜æ¨¡åž‹å’Œæ—¥å¿—
+ train_cfg=train_cfg,
+ train_dataloader=train_dataloader,
+ optim_wrapper=dict(optimizer=optimizer),
+ param_scheduler=lr_scheduler)
+# 执行è®ç»ƒ
+runner.train()
+```
-### 手动构建模å—æ¥ä½¿ç”¨æ‰§è¡Œå™¨
+上é¢çš„例åä¸ï¼Œæˆ‘们手动构建了一个多层感知机网络和手写数å—识别 (MNIST) æ•°æ®é›†ï¼Œä»¥åŠè®ç»ƒæ‰€éœ€è¦çš„优化器和å¦ä¹ 率调度器,使用这些模å—åˆå§‹åŒ–了执行器,并且设置了è®ç»ƒé…ç½® `train_cfg`,让执行器将模型è®ç»ƒ3个轮次,最åŽé€šè¿‡è°ƒç”¨æ‰§è¡Œå™¨çš„ `train` 方法进行模型è®ç»ƒã€‚
-如上文所说,使用执行器的æŸä¸€é¡¹åŠŸèƒ½æ—¶éœ€è¦å‡†å¤‡å¥½å¯¹åº”功能所ä¾èµ–的模å—。以使用执行器的è®ç»ƒåŠŸèƒ½ä¸ºä¾‹ï¼Œç”¨æˆ·éœ€è¦å‡†å¤‡[模型](TODO) ã€[优化器](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/optimizer.html) ã€
-[å‚数调度器](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/param_scheduler.html) 还有è®ç»ƒ[æ•°æ®é›†](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/basedataset.html) 。
-在创建完符åˆä¸Šè¿°æ–‡æ¡£è§„范的模å—的对象åŽï¼Œå°±å¯ä»¥ä½¿ç”¨è¿™äº›æ¨¡å—åˆå§‹åŒ–执行器:
+用户也å¯ä»¥ä¿®æ”¹ `train_cfg` 使执行器按è¿ä»£æ¬¡æ•°æŽ§åˆ¶è®ç»ƒï¼š
```python
-# 准备è®ç»ƒä»»åŠ¡æ‰€éœ€è¦çš„模å—
-model = ResNet()
-optimzier = SGD(model.parameters(), lr=0.01, momentum=0.9)
-lr_scheduler = MultiStepLR(milestones=[80, 90], by_epoch=True)
-train_dataset = ImageNetDataset()
-train_dataloader = Dataloader(dataset=train_dataset, batch_size=32, num_workers=4)
-
-# è®ç»ƒç›¸å…³å‚数设置
-train_cfg = dict(by_epoch=True, max_epoch=100)
-
-# åˆå§‹åŒ–执行器
-runner = Runner(model=model, optimizer=optimzier, param_scheduler=lr_scheduler,
- train_dataloader=train_dataloader, train_cfg=train_cfg)
-# 执行è®ç»ƒ
-runner.train()
+# è®ç»ƒç›¸å…³å‚数设置,按è¿ä»£æ¬¡æ•°è®ç»ƒï¼Œè®ç»ƒ9000次è¿ä»£
+train_cfg = dict(by_epoch=False, max_epoch=9000)
```
-上é¢çš„例åä¸ï¼Œæˆ‘们手动构建了 ResNet 分类模型和 ImageNet æ•°æ®é›†ï¼Œä»¥åŠè®ç»ƒæ‰€éœ€è¦çš„优化器和å¦ä¹ 率调度器,使用这些模å—åˆå§‹åŒ–了执行器,最åŽé€šè¿‡è°ƒç”¨æ‰§è¡Œå™¨çš„ `train` 函数进行模型è®ç»ƒã€‚
+### 手动构建模å—进行测试
å†ä¸¾ä¸€ä¸ªæ¨¡åž‹æµ‹è¯•çš„例å,模型的测试需è¦ç”¨æˆ·å‡†å¤‡æ¨¡åž‹å’Œè®ç»ƒå¥½çš„æƒé‡è·¯å¾„ã€æµ‹è¯•æ•°æ®é›†ä»¥åŠ[评测器](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/evaluator.html) :
```python
-model = FasterRCNN()
-test_dataset = CocoDataset()
-test_dataloader = Dataloader(dataset=test_dataset, batch_size=2, num_workers=2)
-metric = CocoMetric()
+from mmengine.evaluator import BaseMetric
+
+
+class MnistAccuracy(BaseMetric):
+ def process(self, data, preds) -> None:
+ self.results.append(((data[1] == preds.cpu()).sum(), len(preds)))
+ def compute_metrics(self, results):
+ correct, batch_size = zip(*results)
+ acc = sum(correct) / sum(batch_size)
+ return dict(accuracy=acc)
+
+model = Network()
+test_dataset = datasets.MNIST(root="MNIST", download=True, train=False, transform=transforms.ToTensor())
+test_dataloader = DataLoader(dataset=test_dataset)
+metric = MnistAccuracy()
test_evaluator = Evaluator(metric)
# åˆå§‹åŒ–执行器
runner = Runner(model=model, test_dataloader=test_dataloader, test_evaluator=test_evaluator,
- load_from='./faster_rcnn.pth')
+ load_from='./train_mnist/epoch_3.pth', work_dir='./test_mnist')
# 执行测试
runner.test()
```
-这个例åä¸æˆ‘们手动构建了一个 Faster R-CNN 检测模型,以åŠæµ‹è¯•ç”¨çš„ COCO æ•°æ®é›†å’Œä½¿ç”¨ COCO æŒ‡æ ‡çš„è¯„æµ‹å™¨ï¼Œå¹¶ä½¿ç”¨è¿™äº›æ¨¡å—åˆå§‹åŒ–执行器,最åŽé€šè¿‡è°ƒç”¨æ‰§è¡Œå™¨çš„ `test` 函数进行模型测试。
+这个例åä¸æˆ‘们é‡æ–°æ‰‹åŠ¨æž„建了一个多层感知机网络,以åŠæµ‹è¯•ç”¨çš„手写数å—识别数æ®é›†å’Œä½¿ç”¨ (Accuracy) æŒ‡æ ‡çš„è¯„æµ‹å™¨ï¼Œå¹¶ä½¿ç”¨è¿™äº›æ¨¡å—åˆå§‹åŒ–执行器,最åŽé€šè¿‡è°ƒç”¨æ‰§è¡Œå™¨çš„ `test` 函数进行模型测试。
+
+### 手动构建模å—在è®ç»ƒè¿‡ç¨‹ä¸è¿›è¡ŒéªŒè¯
+
+在模型è®ç»ƒè¿‡ç¨‹ä¸ï¼Œé€šå¸¸ä¼šæŒ‰ä¸€å®šçš„间隔在验è¯é›†ä¸Šå¯¹æ¨¡åž‹çš„进行进行验è¯ã€‚在使用 MMEngine 时,åªéœ€è¦æž„建è®ç»ƒå’ŒéªŒè¯çš„模å—,并在è®ç»ƒé…ç½®ä¸è®¾ç½®éªŒè¯é—´éš”å³å¯
+
+```python
+# 准备è®ç»ƒä»»åŠ¡æ‰€éœ€è¦çš„模å—
+optimzier = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
+lr_scheduler = MultiStepLR(milestones=[2], by_epoch=True)
+train_dataset = datasets.MNIST(root="MNIST", download=True, train=True, transform=transforms.ToTensor())
+train_dataloader = DataLoader(dataset=train_dataset, batch_size=10, num_workers=2)
-### 通过é…置文件使用执行器
+# 准备验è¯éœ€è¦çš„模å—
+val_dataset = datasets.MNIST(root="MNIST", download=True, train=False, transform=transforms.ToTensor())
+val_dataloader = Dataloader(dataset=val_dataset)
+metric = MnistAccuracy()
+val_evaluator = Evaluator(metric)
+
+
+# è®ç»ƒç›¸å…³å‚数设置
+train_cfg = dict(by_epoch=True, # 按轮次è®ç»ƒ
+ max_epochs=5, # è®ç»ƒ5è½®
+ val_begin=2, # 从第 2 个 epoch 开始验è¯
+ val_interval=1) # æ¯éš”1轮进行1次验è¯
+
+# åˆå§‹åŒ–执行器
+runner = Runner(model=model, optim_wrapper=dict(optimizer=optimzier), param_scheduler=lr_scheduler,
+ train_dataloader=train_dataloader, val_dataloader=val_dataloader, val_evaluator=val_evaluator,
+ train_cfg=train_cfg, work_dir='./train_val_mnist')
+# 执行è®ç»ƒ
+runner.train()
+```
+
+## 通过é…置文件使用执行器
OpenMMLab çš„å¼€æºé¡¹ç›®æ™®é使用注册器 + é…置文件的方å¼æ¥ç®¡ç†å’Œæž„建模å—,MMEngine ä¸çš„执行器也推è使用é…置文件进行构建。
下é¢æ˜¯ä¸€ä¸ªé€šè¿‡é…置文件使用执行器的例å:
```python
-from mmengine import Config, Runner
+from mmengine import Config
+from mmengine.runner import Runner
# åŠ è½½é…置文件
-config = Config.fromfile('configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py/')
+config = Config.fromfile('configs/resnet/resnet50_8xb32_in1k.py')
# 通过é…置文件åˆå§‹åŒ–执行器
runner = Runner.build_from_cfg(config)
@@ -127,9 +168,13 @@ runner.test()
与手动构建模å—æ¥ä½¿ç”¨æ‰§è¡Œå™¨ä¸åŒçš„是,通过调用 Runner 类的 `build_from_cfg` 方法,执行器能够自动读å–é…置文件ä¸çš„模å—é…置,从相应的注册器ä¸æž„建所需è¦çš„模å—,用户ä¸å†éœ€è¦è€ƒè™‘è®ç»ƒå’Œæµ‹è¯•åˆ†åˆ«ä¾èµ–哪些模å—,也ä¸éœ€è¦ä¸ºäº†åˆ‡æ¢è®ç»ƒçš„模型和数æ®è€Œå¤§é‡æ”¹åŠ¨ä»£ç 。
-下é¢æ˜¯ä¸€ä¸ªå…¸åž‹çš„é…置简å•ä¾‹å:
+下é¢æ˜¯ä¸€ä¸ªå…¸åž‹çš„使用é…置文件调用 MMClassification ä¸çš„模å—è®ç»ƒåˆ†ç±»å™¨çš„简å•ä¾‹å:
```python
+# 工作目录,ä¿å˜æƒé‡å’Œæ—¥å¿—
+work_dir = './train_resnet'
+# 默认注册器域
+default_scope = 'mmcls' # 默认使用 `mmcls` (MMClassification) 注册器ä¸çš„模å—
# 模型é…ç½®
model = dict(type='ImageClassifier',
backbone=dict(type='ResNet', depth=50),
@@ -144,9 +189,11 @@ val_dataloader = ...
test_dataloader = ...
# 优化器é…ç½®
-optimizer = dict(type='SGD', lr=0.01)
+optim_wrapper = dict(
+ optimizer=dict(type='SGD', lr=0.1, momentum=0.9, weight_decay=0.0001))
# å‚数调度器é…ç½®
-param_scheduler = dict(type='MultiStepLR', milestones=[80, 90])
+param_scheduler = dict(
+ type='MultiStepLR', by_epoch=True, milestones=[30, 60, 90], gamma=0.1)
#验è¯å’Œæµ‹è¯•çš„评测器é…ç½®
val_evaluator = dict(type='Accuracy')
test_evaluator = dict(type='Accuracy')
@@ -161,145 +208,54 @@ train_cfg = dict(
val_cfg = dict()
test_cfg = dict()
-# 自定义钩å
+# 自定义钩å (å¯é€‰)
custom_hooks = [...]
-# 默认钩å
+# 默认钩å (å¯é€‰ï¼Œæœªåœ¨é…置文件ä¸å†™æ˜Žæ—¶å°†ä½¿ç”¨é»˜è®¤é…ç½®)
default_hooks = dict(
+ runtime_info=dict(type='RuntimeInfoHook'), # è¿è¡Œæ—¶ä¿¡æ¯é’©å
timer=dict(type='IterTimerHook'), # 计时器钩å
- checkpoint=dict(type='CheckpointHook', interval=1), # 模型ä¿å˜é’©å
+ sampler_seed=dict(type='DistSamplerSeedHook'), # 为æ¯è½®æ¬¡çš„æ•°æ®é‡‡æ ·è®¾ç½®éšæœºç§åçš„é’©å
logger=dict(type='TextLoggerHook'), # è®ç»ƒæ—¥å¿—é’©å
- optimizer=dict(type='OptimzierHook', grad_clip=False), # 优化器钩å
param_scheduler=dict(type='ParamSchedulerHook'), # å‚数调度器执行钩å
- sampler_seed=dict(type='DistSamplerSeedHook')) # 为æ¯è½®æ¬¡çš„æ•°æ®é‡‡æ ·è®¾ç½®éšæœºç§åçš„é’©å
+ checkpoint=dict(type='CheckpointHook', interval=1), # 模型ä¿å˜é’©å
+)
-# 环境é…ç½®
+# 环境é…ç½® (å¯é€‰ï¼Œæœªåœ¨é…置文件ä¸å†™æ˜Žæ—¶å°†ä½¿ç”¨é»˜è®¤é…ç½®)
env_cfg = dict(
- cudnn_benchmark=False,
- dist_cfg=dict(backend='nccl'),
- mp_cfg=dict(mp_start_method='fork')
+ cudnn_benchmark=False, # 是å¦ä½¿ç”¨ cudnn_benchmark
+ dist_cfg=dict(backend='nccl'), # 分布å¼é€šä¿¡åŽç«¯
+ mp_cfg=dict(mp_start_method='fork') # 多进程设置
)
+# 日志处ç†å™¨ (å¯é€‰ï¼Œæœªåœ¨é…置文件ä¸å†™æ˜Žæ—¶å°†ä½¿ç”¨é»˜è®¤é…ç½®)
+log_processor = dict(type='LogProcessor', window_size=50, by_epoch=True)
# 日志ç‰çº§é…ç½®
log_level = 'INFO'
-# åŠ è½½æƒé‡
+# åŠ è½½æƒé‡çš„路径 (None 表示ä¸åŠ è½½)
load_from = None
-# æ¢å¤è®ç»ƒ
+# ä»ŽåŠ è½½çš„æƒé‡æ–‡ä»¶ä¸æ¢å¤è®ç»ƒ
resume = False
```
一个完整的é…置文件主è¦ç”±æ¨¡åž‹ã€æ•°æ®ã€ä¼˜åŒ–器ã€å‚数调度器ã€è¯„测器ç‰æ¨¡å—çš„é…置,è®ç»ƒã€éªŒè¯ã€æµ‹è¯•ç‰æµç¨‹çš„é…置,还有执行æµç¨‹è¿‡ç¨‹ä¸çš„å„ç§é’©å模å—çš„é…置,以åŠçŽ¯å¢ƒå’Œæ—¥å¿—ç‰å…¶ä»–é…置的å—段组æˆã€‚
通过é…置文件构建的执行器采用了懒åˆå§‹åŒ– (lazy initialization),åªæœ‰å½“调用到è®ç»ƒæˆ–测试ç‰æ‰§è¡Œå‡½æ•°æ—¶ï¼Œæ‰ä¼šæ ¹æ®é…置文件去完整åˆå§‹åŒ–所需è¦çš„模å—。
+关于é…置文件的更详细的使用方å¼ï¼Œè¯·å‚考[é…置文件教程](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/config.md)
+
## åŠ è½½æƒé‡æˆ–æ¢å¤è®ç»ƒ
执行器å¯ä»¥é€šè¿‡ `load_from` å‚æ•°åŠ è½½æ£€æŸ¥ç‚¹ï¼ˆcheckpoint)文件ä¸çš„模型æƒé‡ï¼Œåªéœ€è¦å°† `load_from` å‚数设置为检查点文件的路径å³å¯ã€‚
```python
runner = Runner(model=model, test_dataloader=test_dataloader, test_evaluator=test_evaluator,
- load_from='./faster_rcnn.pth')
+ load_from='./resnet50.pth')
```
如果是通过é…置文件使用执行器,åªéœ€ä¿®æ”¹é…置文件ä¸çš„ `load_from` å—段å³å¯ã€‚
-用户也å¯é€šè¿‡è®¾ç½® `resume=True` æ¥ï¼ŒåŠ 载检查点ä¸çš„è®ç»ƒçŠ¶æ€ä¿¡æ¯æ¥æ¢å¤è®ç»ƒã€‚当 `load_from` å’Œ `resume=True` åŒæ—¶è¢«è®¾ç½®æ—¶ï¼Œæ‰§è¡Œå™¨å°†åŠ è½½ `load_from` 路径对应的检查点文件ä¸çš„è®ç»ƒçŠ¶æ€ã€‚如果仅设置 `resume=True`,执行器将会å°è¯•ä»Ž `work_dir` 文件夹ä¸å¯»æ‰¾å¹¶è¯»å–最新的检查点文件。
-
-## 进阶使用
-
-MMEngine ä¸çš„默认执行器能够完æˆå¤§éƒ¨åˆ†çš„深度å¦ä¹ 任务,但ä¸å¯é¿å…会å˜åœ¨æ— æ³•æ»¡è¶³çš„æƒ…å†µã€‚æœ‰çš„ç”¨æˆ·å¸Œæœ›èƒ½å¤Ÿå¯¹æ‰§è¡Œå™¨è¿›è¡Œæ›´å¤šè‡ªå®šä¹‰ä¿®æ”¹ï¼Œå› æ¤ï¼ŒMMEngine 支æŒè‡ªå®šä¹‰æ¨¡åž‹çš„è®ç»ƒã€éªŒè¯ä»¥åŠæµ‹è¯•çš„æµç¨‹ã€‚
-更进一æ¥ï¼Œå¦‚果默认执行器ä¸ä¾ç„¶æœ‰å…¶ä»–æ— æ³•æ»¡è¶³éœ€æ±‚çš„éƒ¨åˆ†ï¼Œç”¨æˆ·å¯ä»¥åƒè‡ªå®šä¹‰å…¶ä»–模å—ä¸€æ ·ï¼Œé€šè¿‡ç»§æ‰¿é‡å†™çš„æ–¹å¼ï¼Œå®žçŽ°è‡ªå®šä¹‰çš„执行器。执行器åŒæ ·ä¹Ÿå¯ä»¥é€šè¿‡æ³¨å†Œå™¨è¿›è¡Œç®¡ç†ã€‚
-
-### 自定义执行æµç¨‹
-
-在 MMEngine ä¸ï¼Œæˆ‘们将任务的执行æµç¨‹æŠ½è±¡æˆå¾ªçŽ¯ï¼ˆLoopï¼‰ï¼Œå› ä¸ºå¤§éƒ¨åˆ†çš„æ·±åº¦å¦ä¹ 任务执行æµç¨‹éƒ½å¯ä»¥å½’纳为模型在一组或多组数æ®ä¸Šè¿›è¡Œå¾ªçŽ¯è¿ä»£ã€‚
-MMEngine 内æ供了四ç§é»˜è®¤çš„循环:
-
-- EpochBasedTrainLoop 基于轮次的è®ç»ƒå¾ªçŽ¯
-- IterBasedTrainLoop 基于è¿ä»£æ¬¡æ•°çš„è®ç»ƒå¾ªçŽ¯
-- ValLoop æ ‡å‡†çš„éªŒè¯å¾ªçŽ¯
-- TestLoop æ ‡å‡†çš„æµ‹è¯•å¾ªçŽ¯
+用户也å¯é€šè¿‡è®¾ç½® `resume=True` æ¥ï¼ŒåŠ 载检查点ä¸çš„è®ç»ƒçŠ¶æ€ä¿¡æ¯æ¥æ¢å¤è®ç»ƒã€‚当 `load_from` å’Œ `resume=True` åŒæ—¶è¢«è®¾ç½®æ—¶ï¼Œæ‰§è¡Œå™¨å°†åŠ è½½ `load_from` 路径对应的检查点文件ä¸çš„è®ç»ƒçŠ¶æ€ã€‚
-
-
-用户å¯ä»¥é€šè¿‡ç»§æ‰¿å¾ªçŽ¯åŸºç±»æ¥å®žçŽ°è‡ªå·±çš„è®ç»ƒæµç¨‹ã€‚循环基类需è¦æ供两个输入:`runner` 执行器的实例和 `loader` 循环所需è¦è¿ä»£çš„è¿ä»£å™¨ã€‚
-用户如果有自定义的需求,也å¯ä»¥å¢žåŠ 更多的输入å‚数。MMEngine ä¸åŒæ ·æ供了 LOOPS 注册器对循环类进行管ç†ï¼Œç”¨æˆ·å¯ä»¥å‘注册器内注册自定义的循环模å—,
-然åŽåœ¨é…置文件的 `train_cfg`ã€`val_cfg`ã€`test_cfg` ä¸å¢žåŠ `type` å—段æ¥æŒ‡å®šä½¿ç”¨ä½•ç§å¾ªçŽ¯ã€‚
-用户å¯ä»¥åœ¨è‡ªå®šä¹‰çš„循环ä¸å®žçŽ°ä»»æ„的执行逻辑,也å¯ä»¥å¢žåŠ æˆ–åˆ å‡é’©å(hook)点ä½ï¼Œä½†éœ€è¦æ³¨æ„的是一旦钩å点ä½è¢«ä¿®æ”¹ï¼Œé»˜è®¤çš„é’©å函数å¯èƒ½ä¸ä¼šè¢«æ‰§è¡Œï¼Œå¯¼è‡´ä¸€äº›è®ç»ƒè¿‡ç¨‹ä¸é»˜è®¤å‘生的行为å‘生å˜åŒ–。
-å› æ¤ï¼Œæˆ‘们强烈建议用户按照本文档ä¸å®šä¹‰çš„循环执行æµç¨‹å›¾ä»¥åŠ[é’©å规范](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/hook.html) 去é‡è½½å¾ªçŽ¯åŸºç±»ã€‚
-
-```python
-from mmengine.registry import LOOPS, HOOKS
-from mmengine.runner.loop import BaseLoop
-from mmengine.hooks import Hook
-
-
-# 自定义验è¯å¾ªçŽ¯
-@LOOPS.register_module()
-class CustomValLoop(BaseLoop):
- def __init__(self, runner, dataloader, evaluator, dataloader2):
- super().__init__(runner, dataloader, evaluator)
- self.dataloader2 = runner.build_dataloader(dataloader2)
-
- def run(self):
- self.runner.call_hooks('before_val_epoch')
- for idx, data_batch in enumerate(self.dataloader):
- self.runner.call_hooks(
- 'before_val_iter', batch_idx=idx, data_batch=data_batch)
- outputs = self.run_iter(idx, data_batch)
- self.runner.call_hooks(
- 'after_val_iter', batch_idx=idx, data_batch=data_batch, outputs=outputs)
- metric = self.evaluator.evaluate()
-
- # å¢žåŠ é¢å¤–的验è¯å¾ªçŽ¯
- for idx, data_batch in enumerate(self.dataloader2):
- # å¢žåŠ é¢å¤–çš„é’©å点ä½
- self.runner.call_hooks(
- 'before_valloader2_iter', batch_idx=idx, data_batch=data_batch)
- self.run_iter(idx, data_batch)
- # å¢žåŠ é¢å¤–çš„é’©å点ä½
- self.runner.call_hooks(
- 'after_valloader2_iter', batch_idx=idx, data_batch=data_batch, outputs=outputs)
- metric2 = self.evaluator.evaluate()
-
- ...
-
- self.runner.call_hooks('after_val_epoch')
-
-
-# 定义é¢å¤–点ä½çš„é’©åç±»
-@HOOKS.register_module()
-class CustomValHook(Hook):
- def before_valloader2_iter(self, batch_idx, data_batch):
- ...
-
- def after_valloader2_iter(self, batch_idx, data_batch, outputs):
- ...
-
-```
-
-上é¢çš„例åä¸å®žçŽ°äº†ä¸€ä¸ªä¸Žé»˜è®¤éªŒè¯å¾ªçŽ¯ä¸ä¸€æ ·çš„自定义验è¯å¾ªçŽ¯ï¼Œå®ƒåœ¨ä¸¤ä¸ªä¸åŒçš„验è¯é›†ä¸Šè¿›è¡ŒéªŒè¯ï¼ŒåŒæ—¶å¯¹ç¬¬äºŒæ¬¡éªŒè¯å¢žåŠ 了é¢å¤–çš„é’©å点ä½ï¼Œå¹¶åœ¨æœ€åŽå¯¹ä¸¤ä¸ªéªŒè¯ç»“果进行进一æ¥çš„处ç†ã€‚在实现了自定义的循环类之åŽï¼Œ
-åªéœ€è¦åœ¨é…置文件的 `val_cfg` 内设置 `type='CustomValLoop'`ï¼Œå¹¶æ·»åŠ é¢å¤–çš„é…ç½®å³å¯ã€‚
-
-```python
-# 自定义验è¯å¾ªçŽ¯
-val_cfg = dict(type='CustomValLoop', dataloader2=dict(dataset=dict(type='ValDataset2'), ...))
-# é¢å¤–点ä½çš„é’©å
-custom_hooks = [dict(type='CustomValHook')]
-```
-
-### 自定义执行器
-
-如果自定义执行æµç¨‹ä¾ç„¶æ— 法满足需求,用户åŒæ ·å¯ä»¥å®žçŽ°è‡ªå·±çš„执行器。具体实现æµç¨‹ä¸Žå…¶ä»–模å—æ— å¼‚ï¼šç»§æ‰¿ MMEngine ä¸çš„ Runner,é‡å†™éœ€è¦ä¿®æ”¹çš„å‡½æ•°ï¼Œæ·»åŠ è¿› RUNNERS 注册器ä¸ï¼Œæœ€åŽåœ¨é…置文件ä¸æŒ‡å®š `runner_type` å³å¯ã€‚
-
-```python
-from mmengine.registry import RUNNERS
-from mmengine.runner import Runner
-
-@RUNNERS.register_module()
-class CustomRunner(Runner):
-
- def setup_env(self):
- ...
-```
+如果仅设置 `resume=True`,执行器将会å°è¯•ä»Ž `work_dir` 文件夹ä¸å¯»æ‰¾å¹¶è¯»å–最新的检查点文件。
-上述例å实现了一个自定义的执行器,并é‡å†™äº† `setup_env` 函数,然åŽæ·»åŠ 进了 RUNNERS 注册器ä¸ï¼Œå®Œæˆäº†è¿™äº›æ¥éª¤ä¹‹åŽï¼Œä¾¿å¯ä»¥åœ¨é…置文件ä¸è®¾ç½® `runner_type='CustomRunner'` æ¥æž„建自定义的执行器。
+ä½ å¯èƒ½è¿˜æƒ³é˜…读[执行器的设计](../design/runner.md)或者[执行器的 API 文档](https://mmengine.readthedocs.io/zh_CN/latest/api/runner.html)。
--
GitLab